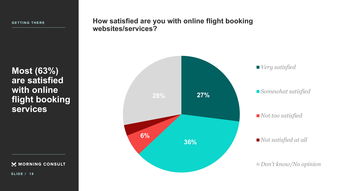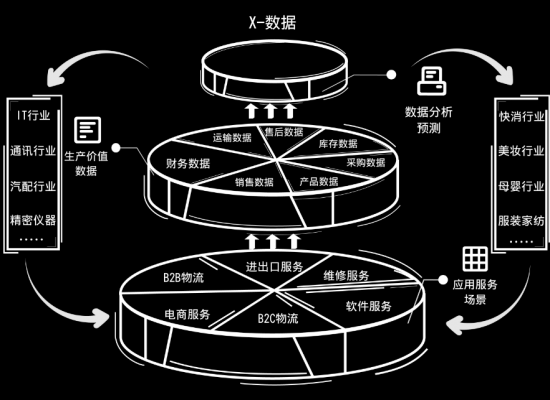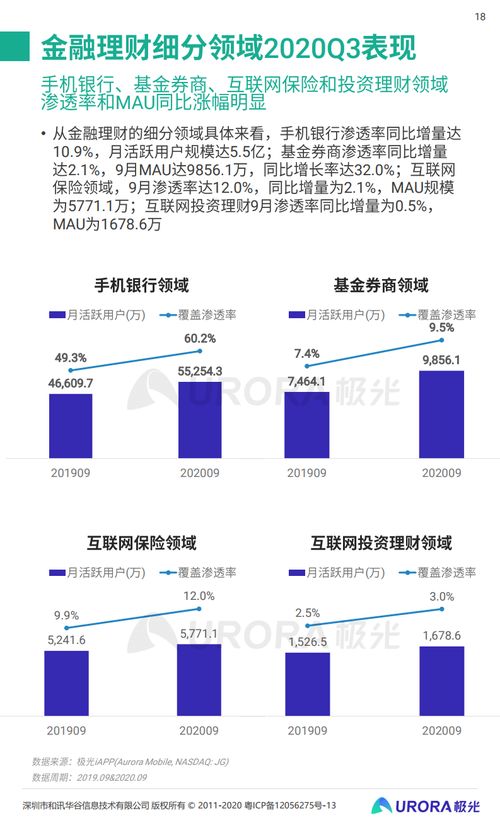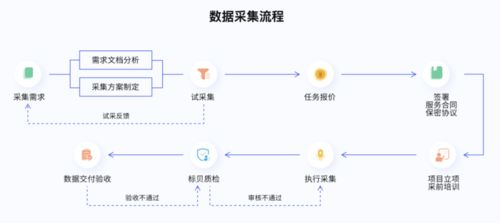
標貝科技在中國科學院《互聯網周刊》聯合發布的2021年數據標注公司排行榜中脫穎而出,彰顯了其在互聯網數據服務領域的卓越實力與行業影響力。這一榮譽不僅是對標貝科技技術能力和服務質量的肯定,更體現了其在推動人工智能數據基礎設施發展中的關鍵作用。
隨著人工智能技術的快速發展,高質量的數據標注成為算法模型訓練的核心支撐。標貝科技憑借先進的數據處理技術、嚴格的質控體系和豐富的行業經驗,為自動駕駛、智能語音、計算機視覺等前沿領域提供了精準、高效的標注服務。其自主研發的智能標注平臺,結合人機協同的作業模式,大幅提升了數據處理的效率和準確性,贏得了眾多頭部企業的信賴與合作。
此次上榜《互聯網周刊》數據標注公司排行榜,進一步鞏固了標貝科技在行業中的領先地位。標貝科技將繼續深耕數據服務領域,以技術創新驅動發展,助力各行各業實現智能化轉型,為構建更智能、更高效的數字化未來貢獻力量。